Audio frequencies may vary based on the volume, pitch and other factors that make up a sound. There are some key facts associated to audio frequencies as described under:
- Human audible frequency range is 20 – 20,000 Hz
- Human speech frequency range is 200 – 9000 Hz
- Telephone channels transmission frequency range is 300 – 3400 Hz
- Nyquist theorem could reproduce frequencies ranging from 300 – 4000 Hz
Though human speed frequency range is between 200 – 9000 Hz and telephone channel transmission frequency range is 300 – 34000 Hz, telephone systems can exactly transmit human conversation by sending only selected / limited range of frequencies. The telephone channel frequency is of good sound quality to identify remote caller. The telephone channel frequency sends only partial spectrum of human voice inflection thus lowering the actual audio quality.
As per Nyquist discovery by sampling at twice the highest frequency we can accurately reproduce an audio signal. So if we refer to audio frequency range 300 – 4000 Hz that means sampling 8000 times (2 * 4000) every second. Sample is a number value. As illustrated in figure 1, in the process of sampling, the device used for sampling puts an analog waveform on Y-axis (numeric values).
Figure 1: Conversion of analog into digital voice signal
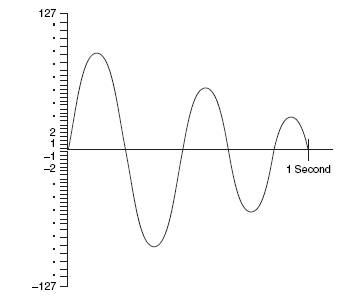
The process of conversion of analog voice signal into digital voice signal is referred as quantization. 1 byte of information represents 0 – 255 values, the quantization of voice signal is limited to – maximum peak of + 127 and maximum low of -127. To arrive at more accurate numeric value, the common frequencies to voice are packed tightly with number value, and the edging frequencies are spread across at the high and low end of spectrum.
The sampling equipment breaks down 8 binary bits in each byte into two parts; a + (positive) or – (negative) indicator and numeric value representation. Figure 2 shows the initial bit indicates + / – value and rest 7 bits present the actual number value.
Figure 2: Voice encoding into number values
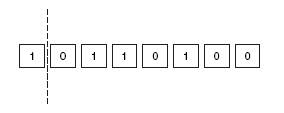
The first bit is 1 which indicates a positive value. The rest 7 bits present number 52 that would be digital value used for one voice sample. As per Nyquist theorem, 8000 of samples every second is required, with 8 bits in each sample comes to 64,000 bits per second. And an uncompressed audio/G.711 audio codec also requires 64 Kbps. Once the sampling process is complete the router is used to place in a packet for transmission over a network.
The compression is an optional process in digitization of analog signals. Codes such as G.729 allow compression of number of samples sent and use less bandwidth. The G.729 process compresses the audio to send a sound sample once and inform remote device to continuously play that particular sound for a fixed duration. This is also referred as “building a codebook” for human voice travelling between two endpoints. G.729 reduces bandwidth up to 8 Kbps per call.
Reducing the bandwidth involves cost. Quality is impacted during the compression. The measurement system known as Mean Opinion Score (MOS) is used in the early digitization years to measure the quality of voice codecs.
Quality of voice is measured by – caller saying a sentence and listener will listen and rate the voice clarity on the scale of 1 – 5. Table 1 shows how different codecs resulted in MOS testing:
Table 1: Audio codec bandwidth with MOS values
|
Codec |
Bandwidth consumption |
MOS |
|
G.711 |
64 Kbps |
4.1 |
|
Internet low Bit rate codec (iLBC) |
15.2 Kbps |
4.1 |
|
G.729 |
8 Kbps |
3.92 |
|
G.726 |
32 Kbps |
3.85 |
|
G.729a |
8 Kbps |
3.7 |
|
G.728 |
16 Kbps |
3.61 |
There are different kinds of codecs meant to address different kinds of network requirements . Like certain codes are designed for military operations where streamlined transmission is more important than voice quality. Cisco designed IP phones are provide coding into two formats G.711 and G.729. G.711 is the commonly used codec for all IP devices. This concludes our CCNA Voice lesson on voice packetization. In this lesson we learned how analog voice signals are converted into digital voice signals and transmitted over the network.